
FFHQ Dataset
Flickr Faces High-Quality (FFHQ) is a dataset of Flickr face photos originally created for face generation research by NVIDIA in 2019. It includes 70,000 total face images from 67,646 unique Flickr photos. Since its release the dataset has become of the most widely used face datasets for a wide variety of research and commercial applications ranging from face recognition to oral region gender recognition. The images in FFHQ were taken from Flickr users without explicit consent and were selected because they contained high quality face images with a permission Creative Commons license. Many of the images contain infants and children and over 10% of the dataset no longer exists on the original source yet NVIDIA, a $1T company, continues to use and benefit from the 70,000 face images taken on Flickr.com to develop commercial AI technologies.
The official dataset page https://github.com/NVlabs/ffhq-dataset includes detailed metadata for all images, scripts to automate downloading, direct download links with all images (to bypass Flickr.com), and charts detailing the image license distribution. On their dataset page the authors stated they "are committed to protecting the privacy of individuals who do not wish their photos to be included." To mitigate the harms or potential legal liability the NVIDIA researchers provide a basic search engine on their site and instructions for removal, specifically noting that if the photo is made private, removed, or hidden on Flickr it can be removed from the dataset by additionally emailing an NVIDIA representative.
The problem with NVIDIA's proposed "opt-out" system is that no one ever opted in. All 70,000 images were taken without explicit consent from either the photographer or the subject. In total the dataset includes high quality face photos from 14,522 unique Flickr accounts amounting to a 67,646 unique photos from which 70,000 face crops were selected and then use to create the FFHQ dataset.
It is not yet clear if NVIDIA would follow through with their privacy claim to remove face images from the FFHQ dataset because it could have significant negative downstream effects on their AI models. For example, the StyleGAN3 model offered by NVIDIA is trained on all 70,000 images from FFHQ. If any image were to be removed the entire model would need to retrained, as as well any other AI products developed using FFHQ data. The NVIDIA website claims to have a "mechanism in place to honor data subject right of access or deletion of personal data" (see NVIDIA's PlusPlus++ Promise), which implies they are open to and accepting data removal requests.
Exposing.ai provides a search engine to check if your images were used by NVIDIA in the FFHQ dataset. Simply type in your Flickr username, photo ID, or you can also search using a hashtag (e.g. #defcon, #comiccon). If a result is found, one must also email NVIDIA at the address provided here https://github.com/NVlabs/ffhq-dataset#privacy. No search input is recorded by Exposing.ai.
This page will be updated with any successful (or unsuccessful) data removal request stories. In the meantime Exposing.ai has conducted a preliminary review of several issues with the FFHQ dataset.
Data Review
| Categroy | Problems | Description |
|---|---|---|
| Biometric Data | Yes | biometric data is being distributed by the NVIDIA FFHQ dataset in the form of a 68-point facial landmark describing the key facial features. It is sometimes also associated with the name, as shown on their Github dataset page |
| Non-Consensual Data | Yes | No explicit consent was provided in order to obtain the Flickr images. They were downloaded from Flickr and automatically filtered using various face processing software |
| PII Data | Yes | The dataset is distributed with real names in the metadata file, sometimes included in the "author" field. |
| Rogue Data | Yes | The data is used for purposes far beyond the original use. Even the dataset authors have addressed the misuse for face recognition and urge to avoid this application. However, it is widely used for biometric and other purposes beyond original intended use. |
| Zombie Data | Yes | FFHQ includes zombie data, or data that has been removed from the original source but still persists in the dataset. Approximately 10% of FFHQ is zombie data |
Based on the dataset review (details below), Exposing.ai recommends deleting and deprecating FFHQ data and any derivatives for all "high-risk" and "unacceptable risk" AI research. The "high risk" label is used to describe applications "that negatively affect safety or fundamental rights will be considered high risk and will be divided into two categories". The "unacceptable risk" label includes "real-time and remote biometric identification systems, such as facial recognition" (see: EU AI Act risk level explanations). FFHQ has not only been used for gender recognition but also other forms of soft-biometrics, for example in Biometrics and Deep Learning: Detecting Facial Soft Biometrics Features Using Ocular and Forehead Region for Masked Face Images, the FFHQ face images are used for face recognition based on the forehead subregion.
Additionally, NVIDIA should delete all personally identifiable (real names) information in the FFHQ metadata files, biometric data (facial landmarks) information included in the FFHQ metadata files, remove inactive Flickr images (over 7,000), and purge company AI models of deprecated data.
For academic conferences, like NeurIPS.cc, Exposing.ai recommends that FFHQ is prohibited in submissions that engage in high-risk or unacceptable-risk research including gender estimation, face recognition and other remote biometric technologies. Another important criteria for datasets used in academic, or commercial research, is that the data was obtained with consent. Because no consent was obtained for any faces in FFHQ it's also advisable to disallow the entire dataset for any academic conference.
Zombie Data
When images are removed, hidden, or made private on Flickr they still persist in the FFHQ dataset. Exposing.ai analyzed the recent Flickr API metadata for all 67,646 images in the FFHQ dataset in 2019 and again in August 2023. The results showed that in 2019 there were 3,262 FFHQ photos removed or made private Flickr. And in 2023 that number more than doubled to 7,734 photos. Currently over 10% of the FFHQ dataset has been removed from or made private on Flickr yet continues to persist in the FFHQ dataset. Because NVIDIA distributes the dataset images directly via a Google Drive link, deleting an image on Flickr unfortunately has no effect on its status in the FFHQ dataset.
Although NVIDIA claims that "to get your photo removed from the Flickr-Faces-HQ dataset" one must remove it from Flickr, they also require the Flickr user to follow up with an email to their research department with their Flickr username. Upon deletion, a Flickr users could only (potentially) remove an image from the dataset distributed by NVIDIA. All other copies of the dataset would still retain the "zombie data" 4. The individuals in the dataset would have no possible recourse for deleting their faces in the tens of thousands of copies downloaded around the world.
Rouge Data
Several years after publishing the dataset the NVIDIA researchers addressed an growing problem with the dataset. Even though they created it for generative AI, there was no meaningful restriction on how the data could be used for other research. And it was already perfectly formatted for other facial analysis research including face recognition. On March 8, 2022 the NVIDIA researchers edited their README to advise against using their dataset of 70,000 faces for face recognition. But it was too little and too late. The dataset had already propagated through research networks and was accelerating the global surveillance economy.
Since it's publication in 2019 the FFHQ dataset has become of the most widely used, well organized face datasets. It is the data driving projects including soft biometrics and forehead analysis, masked face classification/recognition, and "real-world human gender classification from oral region" to name only a few. On Google Scholar, a popular research hub, there are over 2,600 research papers listed that use or reference the dataset. On Semantic Scholar, another widely use reference site for research there are a staggering 1 million (unfiltered) results that mention the "FFHQ dataset" as of August 2023.
It also appears frequently in patents. A simple search for "FFHQ" on Google Patents reveals over 255 patent publications that rely on or use the 70,000 FFHQ face images. The patents primarily relate to technologies for generative AI, but extend to biometric applications including face recognition. For example, a Chinese patent CN112750082B uses FFHQ images to enhance face recognition with super-resolution algorithms trained on FFHQ data.

NVIDA, who created the FFHQ dataset, has been awarded at least 11 patents for commercial technology based on research that relies upon the FFHQ data. Notably, NVIDIA specifically notes that the FFHQ dataset images and the JSON dataset (list of images) can only be used for "non-commercial purposes". That also didn't prevent Adobe, Inc. from benefiting. They were awarded at least 8 patents for technology developed using the FFHQ data, ranging from generative AI to face editing software.
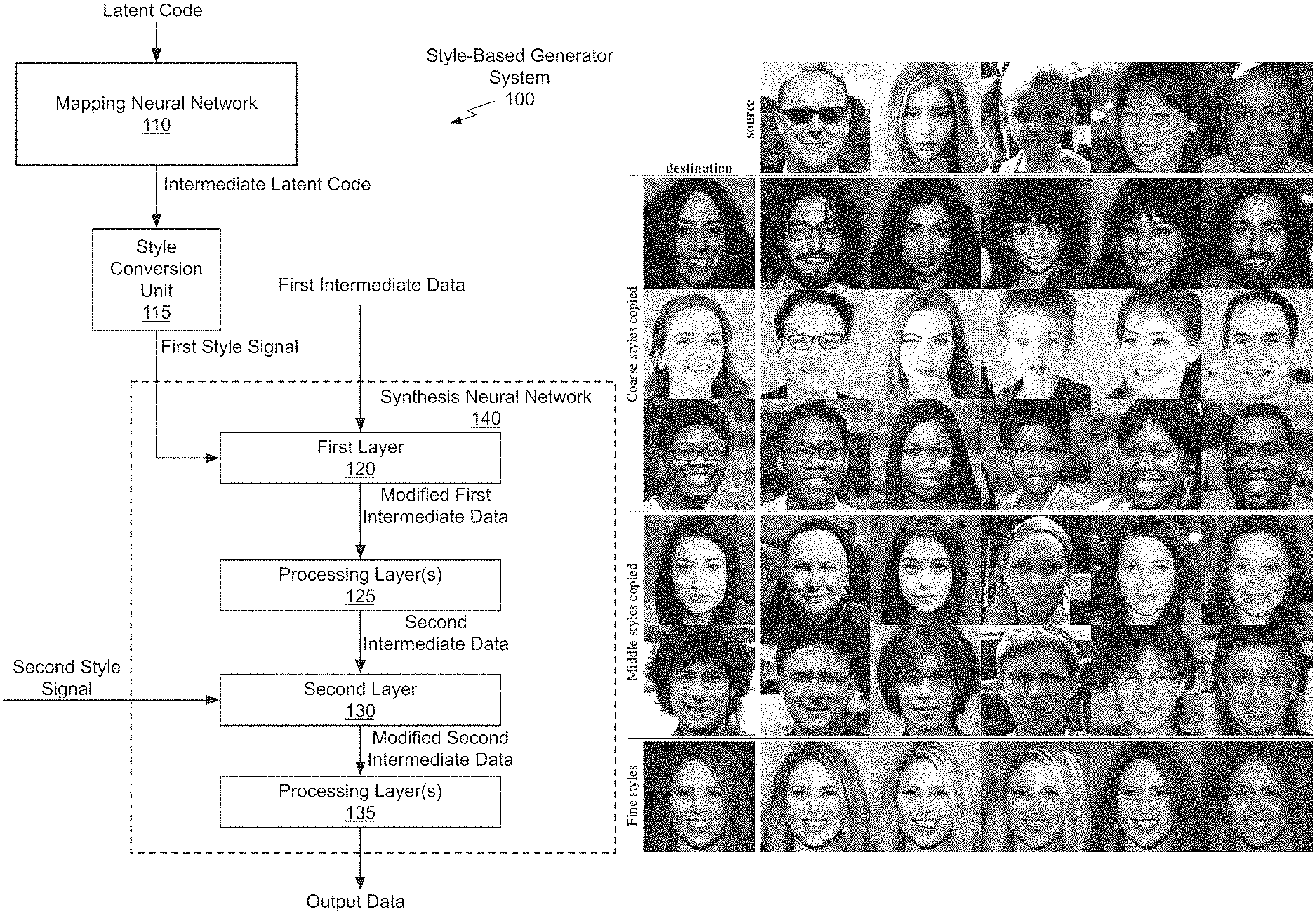
Derivative Datasets
Since FFHQ was published in 2019 its popularity has led to several derivative datasets. In 2020 academic and commercial researchers from University of Washington, Stanford, and Adobe created the FFHQ-Aging dataset for "Lifespan Age Transformation Synthesis" with the goal of predicting "a full head portrait for ages 0–70 from a single photo." 3
The aging dataset appends further biometric information to the original NVIDA FFHQ dataset. Originally, NVIDIA included only 68-pt facial landmarks. According to the class-action lawsuit filed against IBM for their Diversity in Faces dataset, the 68-point landmark attributes likely qualify as a form of biometric data. The aging dataset extends the biometric data further by adding gender attributes, a category of information that has repeatedly been labeled as outdated, unacceptable, and easily abused.

Another version of the dataset (https://github.com/DCGM/ffhq-features-dataset) posted to Github includes more detailed information for each face including emotion, age, gender, head pose, smile, and facial hair variables.
Then in 2021 another derivative dataset called FFHQR, or Flickr-Faces-HQ-Retouching, was created for the purpose of developing automated photo retouching software. The company that created it, Skylab Technologies, provides automated retouching software for approximately $0.10 / photo, a clearly commercial end use of the FFHQ dataset images if it can be proved their models include it. The company's video indicate one of the keys to their success is "large scale training data", which is described in their white paper as comprising the 70,000 face images from FFHQ along with other studio images. According to the paper they "use 56,000 [FFHQ] images for training, 7000 [FFHQ] images for validation, and 7000 [FFHQ] images for testing." 2 This points to the likely conclusion that Skylab Technologies retouching software is built in part using the original and retouched faces in the FFHQ dataset.

Then, again, in 2023 the dataset was used to create FFHQ-UV, a normalized facial UV-texture dataset for 3D face reconstruction by researchers from Nanjing University and Tencent AI Lab. According to their FFHQ-UV: Normalized Facial UV-Texture Dataset for 3D Face Reconstruction paper "results indicate that the proposed 3D face reconstruction algorithm, based on the GAN-based texture de-coder trained with the proposed FFHQ-UV dataset, is able to improve the reconstruction accuracy in terms of both shape and texture," but the final object of the research is unclear. The 3D face reconstructions could be used for either image editing, gaming, or to enhance face recognition.

Data Distributors
Who's still hosting the FFHQ dataset?
The main distribution point for FFHQ face dataset remains on the official NVIDIA Github page at https://github.com/NVlabs/ffhq-dataset/. Because of it's popularity, the dataset has spread to many other platforms. The AI research website HuggingFace hosts the files in at least 3 data repositories (https://huggingface.co/datasets/AyoubChLin/FFHQ/, https://huggingface.co/datasets/cr7Por/ffhq_controlnet_5_2_23, and https://huggingface.co/datasets/Ryan-sjtu/ffhq512-caption). As is evident in the dataset preview, the dataset includes many infants and children. Based on age data distributed in a derivative dataset age distribution is as follows: age 0-6 = 6753, age 6-12 = 3702, age 12-18 = 2126, age 18-36 = 34854, age 36-48 = 12209, age 48-60 = 6991, age 60-100 = 2836.
Using the FFHQ dataset for developing AI models has become so normalized that the full dataset comes preinstalled with software development kits. Snark AI (aka Activeloop) allows developers to import the full dataset from their servers with just 2 lines of code:
import deeplake
ds = deeplake.load("hub://activeloop/ffhq")
This may be convenient for developers but it completely bypasses the legal requirements of the creators and individuals at the mercy of a permissive Creative Commons license, which required attribution at the very least. Many (almost half) also specified non-commercial use. How is it possible to comply with attribution and non-commercial license restrictions when the data is automatically downloaded in a commercial AI product? It simply does not compute.
Creative Commons Attribution Denied
Even though the main dataset and its derivatives mention the Creative Commons licenses associated with the media, of which many require attribution, no human readable attribution was provided for any photo in any dataset. Attribution is only provided in a 256MB JSON file that could not be opened on a standard laptop computer using Sublime text editor, let alone parsed to understand author attribution. This may amount to a large-scale breach of the Creative Commons attribution requirement. For further reading on the exploitation of Creative Commons licensing scheme, read "Creative Commons and The Face Recognition Problem". To further complicate the issue, it may not be possible at all to use non-consensual face images for AI/ML when attribution is required because including the subject or author name can force the face photo to become PII (personally identifiable information), a protected class of data.
Supplemental Data
FFHQ Copyright Distribution

FFHQ Creative Commons License Distribution

FFHQ Image Upload Year Distribution

Top 10 FFHQ Image #Tags

Top 10 Geocoded Cities FFHQ

Citing This Work
If you reference or use any data from the Exposing.ai project, cite our original research as follows:
@online{Exposing.ai,
author = {Harvey, Adam. LaPlace, Jules.},
title = {Exposing.ai},
year = 2021,
url = {https://exposing.ai},
urldate = {2021-01-01}
}
If you reference or use any data from FFHQ cite the author's work:
@article{Karras2019ASG,
author = "Karras, Tero and Laine, S. and Aila, Timo",
title = "A Style-Based Generator Architecture for Generative Adversarial Networks",
journal = "2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)",
year = "2019",
pages = "4396-4405"
}
References
- 1 Tero Karras, et al. "A Style-Based Generator Architecture for Generative Adversarial Networks". 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). (2019): 4396-4405.
- 2 aAlireza Shafaei. "AutoRetouch: Automatic Professional Face Retouching". 2021 IEEE Winter Conference on Applications of Computer Vision (WACV). (2021): 989-997.
- 3 aRoy Or-El, et al. "Lifespan Age Transformation Synthesis". ArXiv abs/2003.09764. (2020):
- 4 aAlex, et al. "A Framework for Deprecating Datasets: Standardizing Documentation, Identification, and Communication". (2022):